🌇 Hi there👋🏻, I am currently a Staff Researcher at International Digital Economy Academy (IDEA) .
I am now leading an effort on talking head generation, face tracking, humuan video generation, human-centric 3DGS and video content generation research. If you are seeking any form of academic cooperation, please feel free to email me at liuyunfei@idea.edu.cn.
.
I am now leading an effort on talking head generation, face tracking, humuan video generation, human-centric 3DGS and video content generation research. If you are seeking any form of academic cooperation, please feel free to email me at liuyunfei@idea.edu.cn.
I got my Ph.D. degree from Beihang University, advised by Prof. Feng Lu. Previously, I received my BSc degree in Computer Science from Beijing Institute of Technology in 2017.
My research aims to build multimodal, highly expressive, lifelike, and immersive interactive agents, covering perception, understanding, reconstruction, and generation of humans and the world. Specifically:
-
👀 Human–environment interaction perception: PnP-GA, GazeOnce, WISWYS.
-
😏 2D/3D Head and body reconstruction, animation, and generation: TEASER, GUAVA, GPAvatar, MODA, HRAvatar, DiffSHEG, TokenFace.
-
🎞 Image/Video editing and generation: Qffusion, STEM-inv, AddMe.
Previously, I also worked on Physical-based Low-level Vision (e.g., USI3D, SGRRN, SILS), Network Interpretability (Refool), AR/VR (EGNIA, 3DEG), and Industrial Anomaly Detection (UTAD).
I serve as a reviewer for international conferences and journals, e.g., CVPR, ICCV, NeuIPS, ICLR, ICML, ACM MM, TPAMI, IJCV, PR, TVCG, etc..
👏 We are currently looking for self-motivated interns to explore cutting-edge techniques such as Gaussian Splatting and DM/FM. Feel free to contact me if you are interested. zhihu
🔥 News
- [March, 2026]: 🎉 One SIGGRAPH paper is accepted. Project and codes are released, welcome to star us!
- [March, 2026]: 🎉 I serve as a Area Chair for ICPR 2026.
- [July, 2025]: 🎉 One TVCG paper is accepted. Project and demos are coming soon.
- [July, 2025]: 🎉 I will serve as a Program Committee for AAAI 2026.
- [June, 2025]: 🎉 Two ICCV papers are accepted. Codes and demos are coming soon.
- [May, 2025]: 🎉 We introcuce GUAVA, a new Upper Body 3D Gaussian Avatar.
- [May, 2025]: 🎉 The code of
HRAvatarhas been released. - [March, 2025]: 🎉 The code of
TEASERhas been released. - [February, 2025]: 🎉 Our
HRAvatarhas been accepted to CVPR 2025. -
[Jan, 2025]: 🎉 Our
TEASERhas been accepted to ICLR 2025. - [2024]: 5 papers have been accepted by ICLR, CVPR, AAAI, ECCV.
Click for More
- [December, 2024]: 🎉 One <a href=https://aaai.org/Conferences/AAAI-25/>AAAI</a> paper has been accepted.
- [August, 2024]: I will serve as a Program Committee for <a href=https://aaai.org/conference/aaai/aaai-25/>AAAI 2025</a>.
- [July, 2024]: One paper is accepted to <a href=https://eccv.ecva.net/virtual/2024/papers.html>ECCV 2024</a>.
- [February, 2024]: Two <a href=https://cvpr2024.thecvf.com/>CVPR 2024</a> papers have been accepted.
- [Jan, 2024]: 🎉 Our
GPAvatarhas been accepted to ICLR 2024. - [December, 2023]: 🎉 Our
PnP-GA+has been accepted by TPAMI. - [July, 2023]: 🎉 Two ICCV papers have been accepted.
- [June, 2023]: 🎉 One TPAMI paper has been published.
- [April, 2023]: 🎉 One CVMJ paper has been accepted.
- [Mar, 2022]: 🎉 Two CVPR papers have been accepted.
📝 Publications
📩 denotes corresponding author, 📌 denotes co-first author.

🍐 PEAR :Pixel-aligned Expressive humAn mesh Recovery
Jiahao Wu, Yunfei Liu📩, Lijian Lin, Ye Zhu, Lei Zhu, Jingyi Li, Yu Li
- 🙆♂️ We propose PEAR, a unified framework for real-time expressive 3D human mesh recovery.
- ⚡️ It is the first method capable of simultaneously predicting EHM-s parameters at 100 FPS.

MANGO:Natural Multi-speaker 3D Talking Head Generation via 2D-Lifted Enhancement
Lei Zhu, Lijian Lin, Ye Zhu, Jiahao Wu, Xuehan Hou, Yu Li, Yunfei Liu📩, Jie Chen📩
- 🧠 We propose MANGO, a two-stage framework using image-level supervision for realistic multi-speaker 3D motion and natural bidirectional listen-and-speak conversational behavior.
- 🎭 With the MANGO-Dialog dataset, our method achieves highly accurate and controllable 3D dialogue heads.
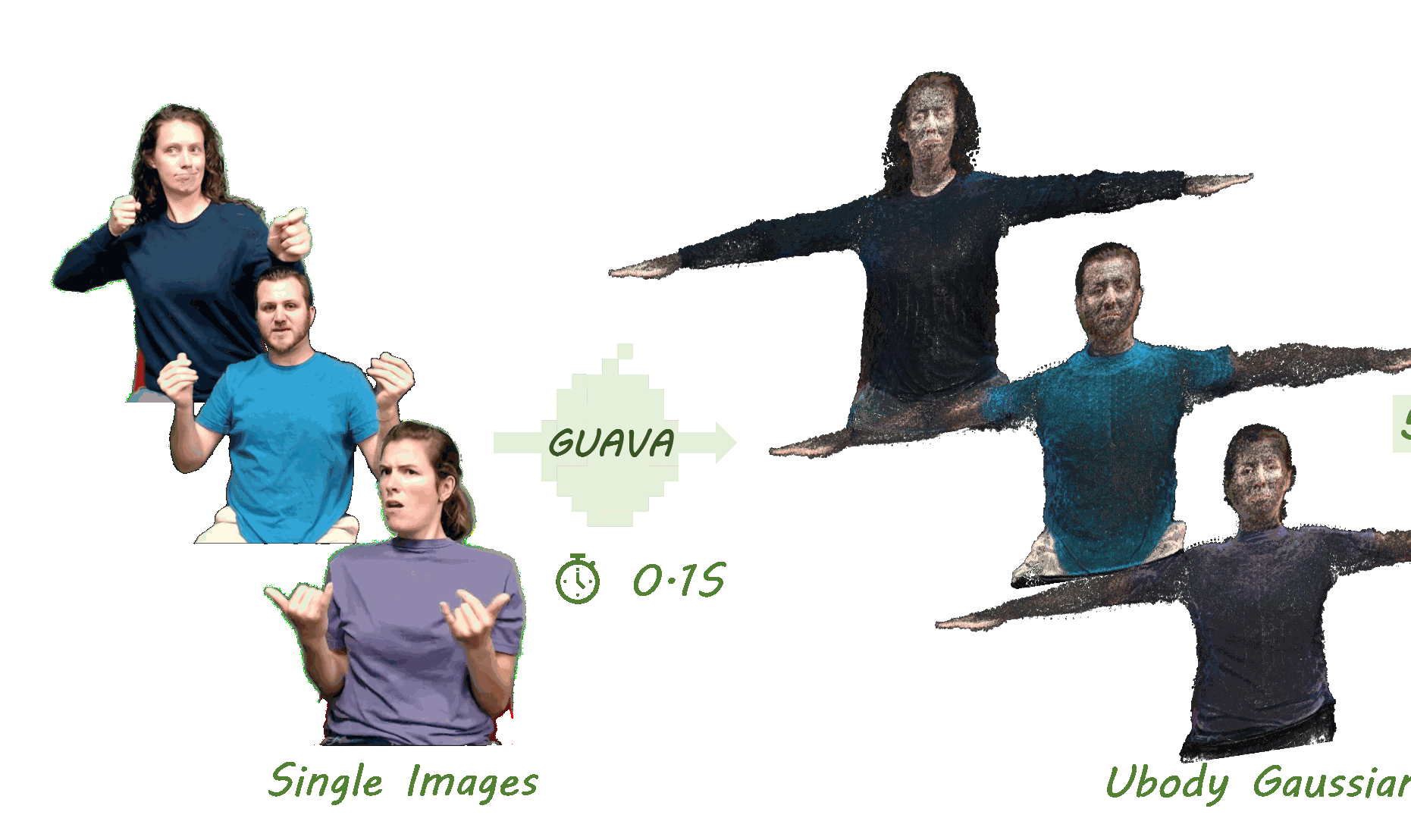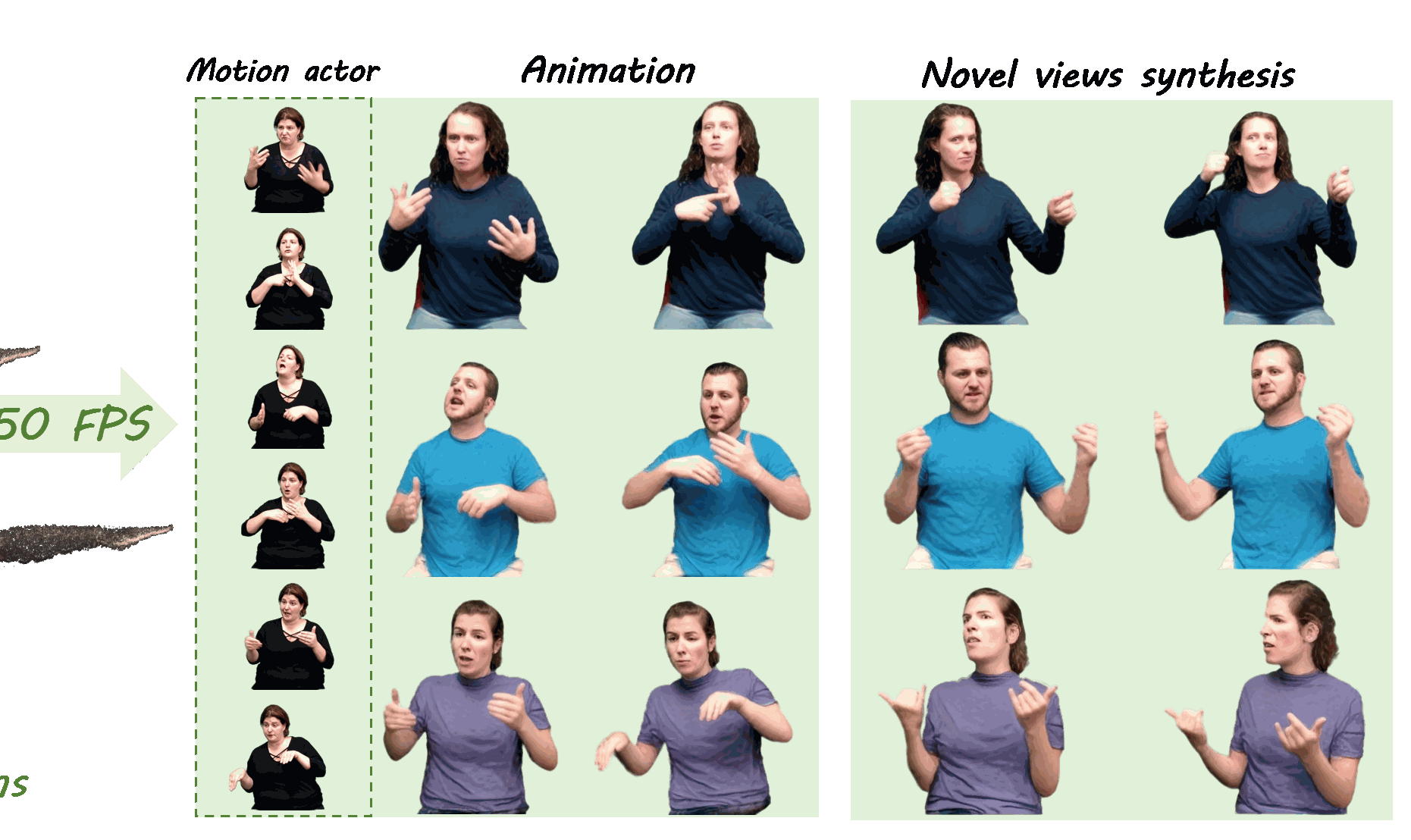
GUAVA: Generalizable Upper Body 3D Gaussian Avatar
Dongbin Zhang, Yunfei Liu📩, Lijian Lin, Ye Zhu, Yang Li, Minghan Qin, Yu Li, Haoqian Wang📩
- ⚡️ Reconstructs 3D upper-body Gaussian avatars from single image in 0.1s
- ⏱️ Supports real-time expressive animation and novel view synthesis at 50FPS !
HRAvatar: High-Quality and Relightable Gaussian Head Avatar
Dongbin Zhang, Yunfei Liu, Lijian Lin, Ye Zhu, Kangjie Chen, Minghan Qin, Yu Li, Haoqian Wang
- We propose HRAvatar, a 3D Gaussian Splatting-based method that reconstructs high-fidelity, relightable 3D head avatars from monocular videos by jointly optimizing tracking, deformation, and appearance modeling.
- By leveraging learnable blendshapes, physically-based shading, and end-to-end optimization, HRAvatar significantly improves head quality and realism under novel lighting conditions.

TEASER: Token Enhanced Spatial Modeling for Expressions Reconstruction
Yunfei Liu📌, Lei Zhu📌, Lijian Lin, Ye Zhu, Ailing Zhang, Yu Li
- A novel approach that achieves more accurate facial expression reconstruction by predicting a hybrid representation of faces from a single image.
- A multi-scale facial appearance tokenizer and a token-guided neural renderer to generate high-fidelity facial images. The extracted token is interpretable and highly disentangled, enabling various downstream applications.
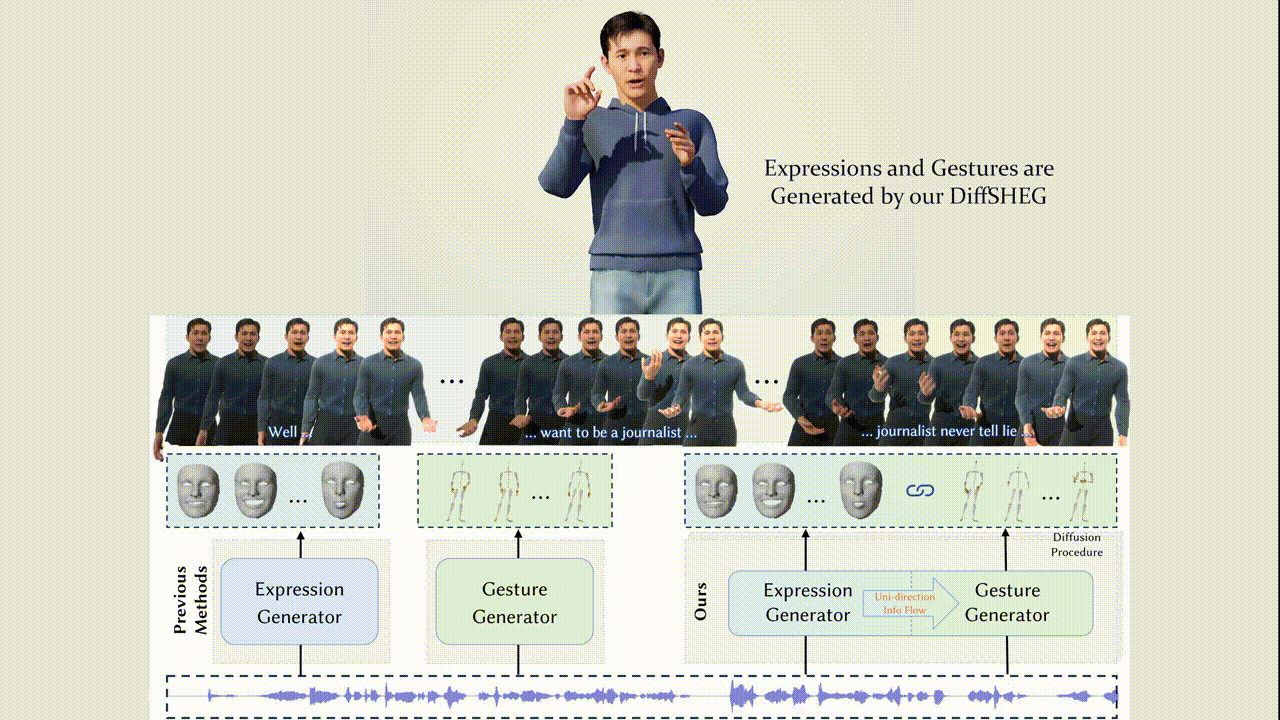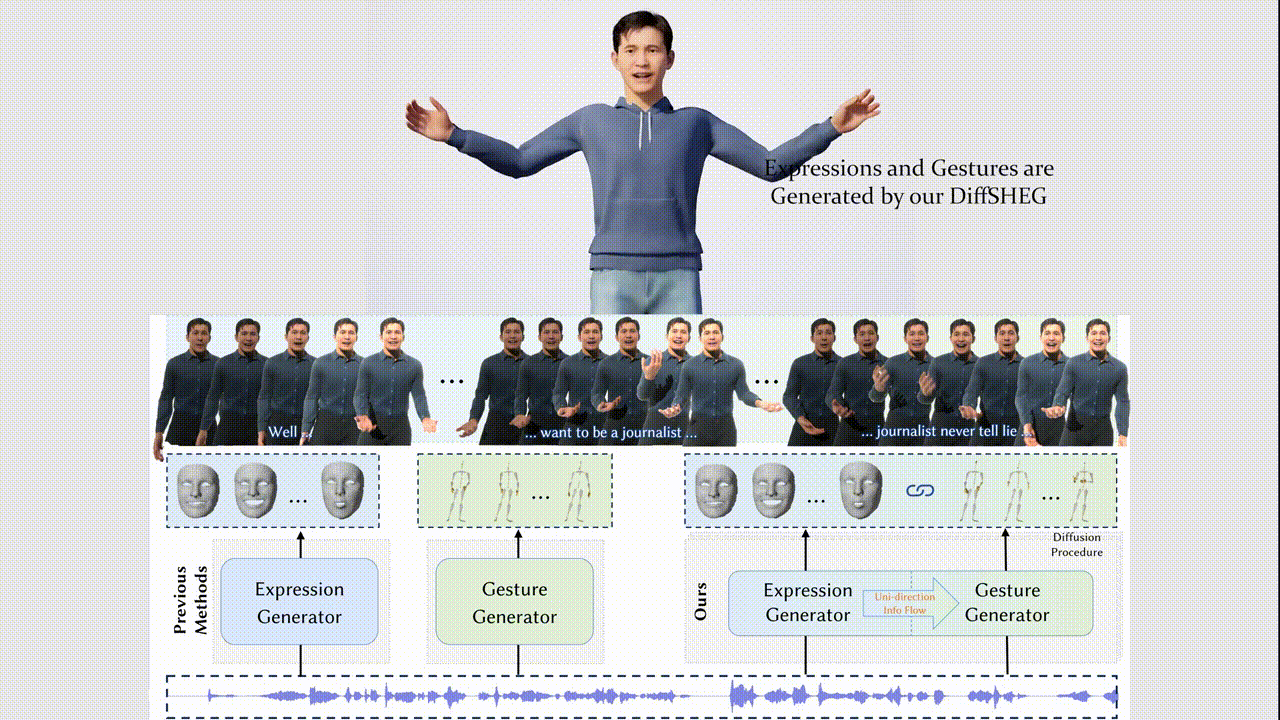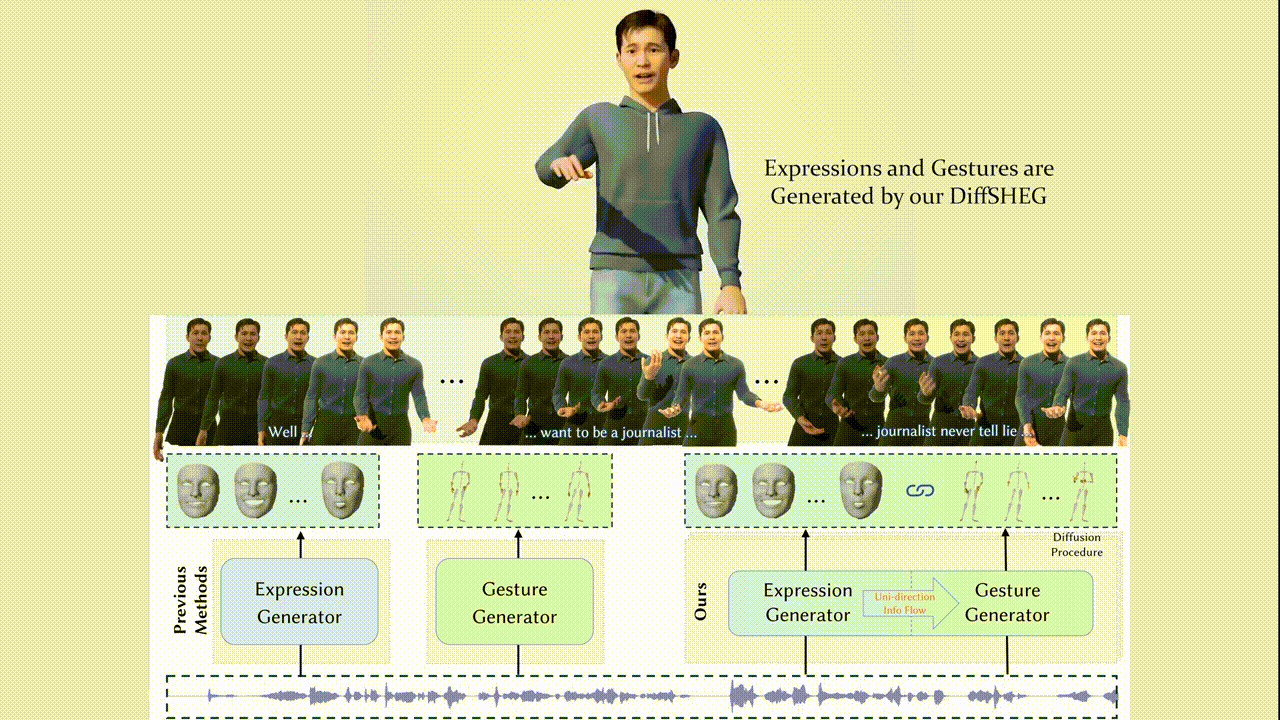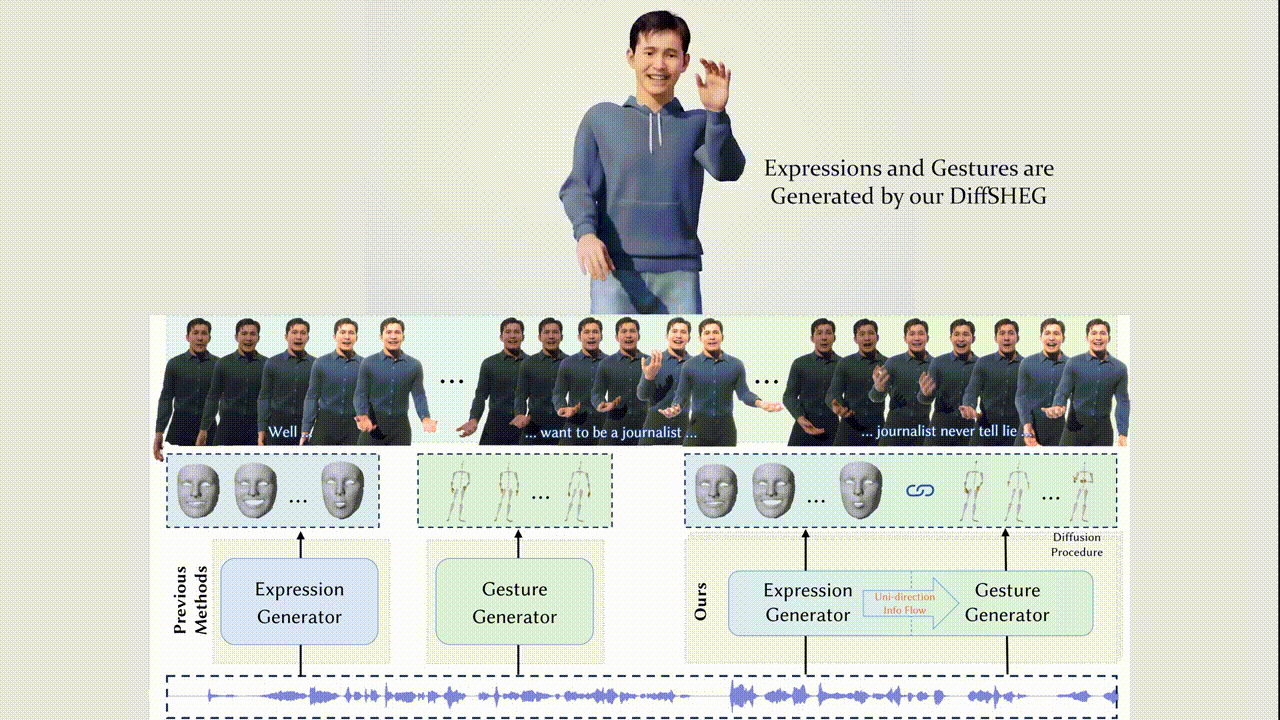
Junming Chen, Yunfei Liu, Jianan Wang, Ailing Zeng, Yu Li, Qifeng Chen
- We propose DiffSHEG, a Diffusion-based approach for Speech-driven Holistic 3D Expression and Gesture generation with arbitrary length.
- Our diffusion-based co-speech motion generation transformer enables uni-directional information flow from expression to gesture, facilitating improved matching of joint expression-gesture distributions
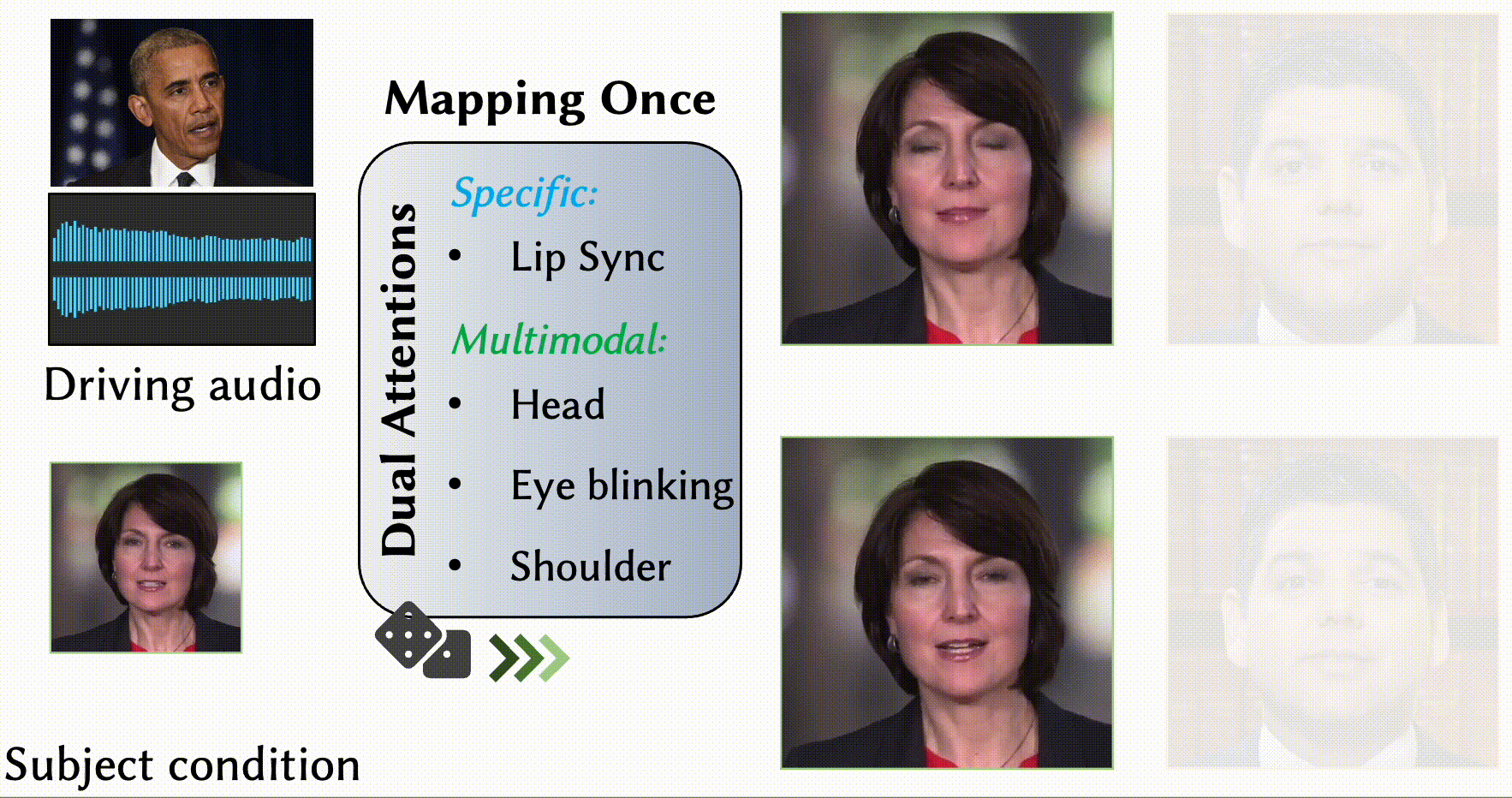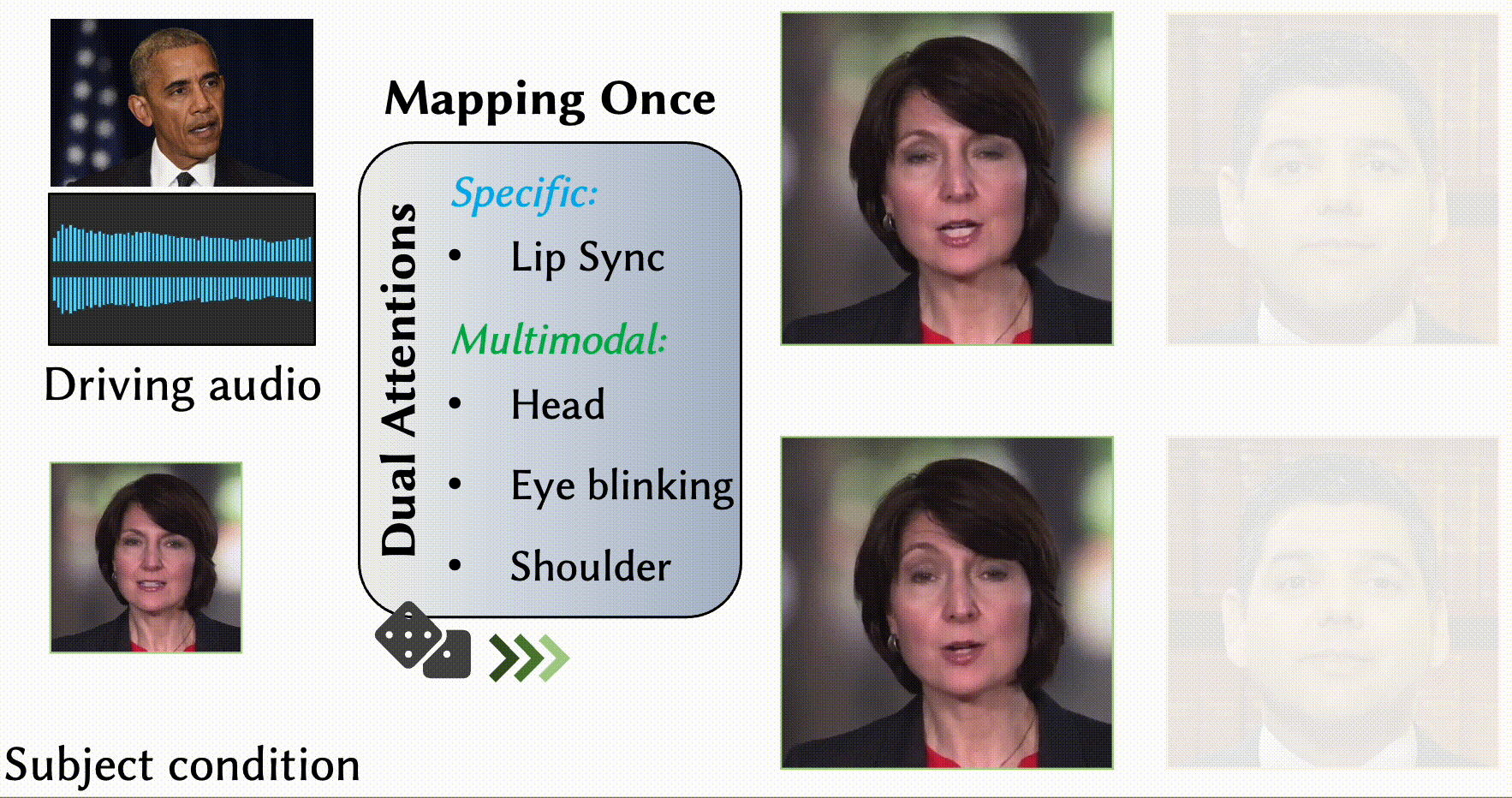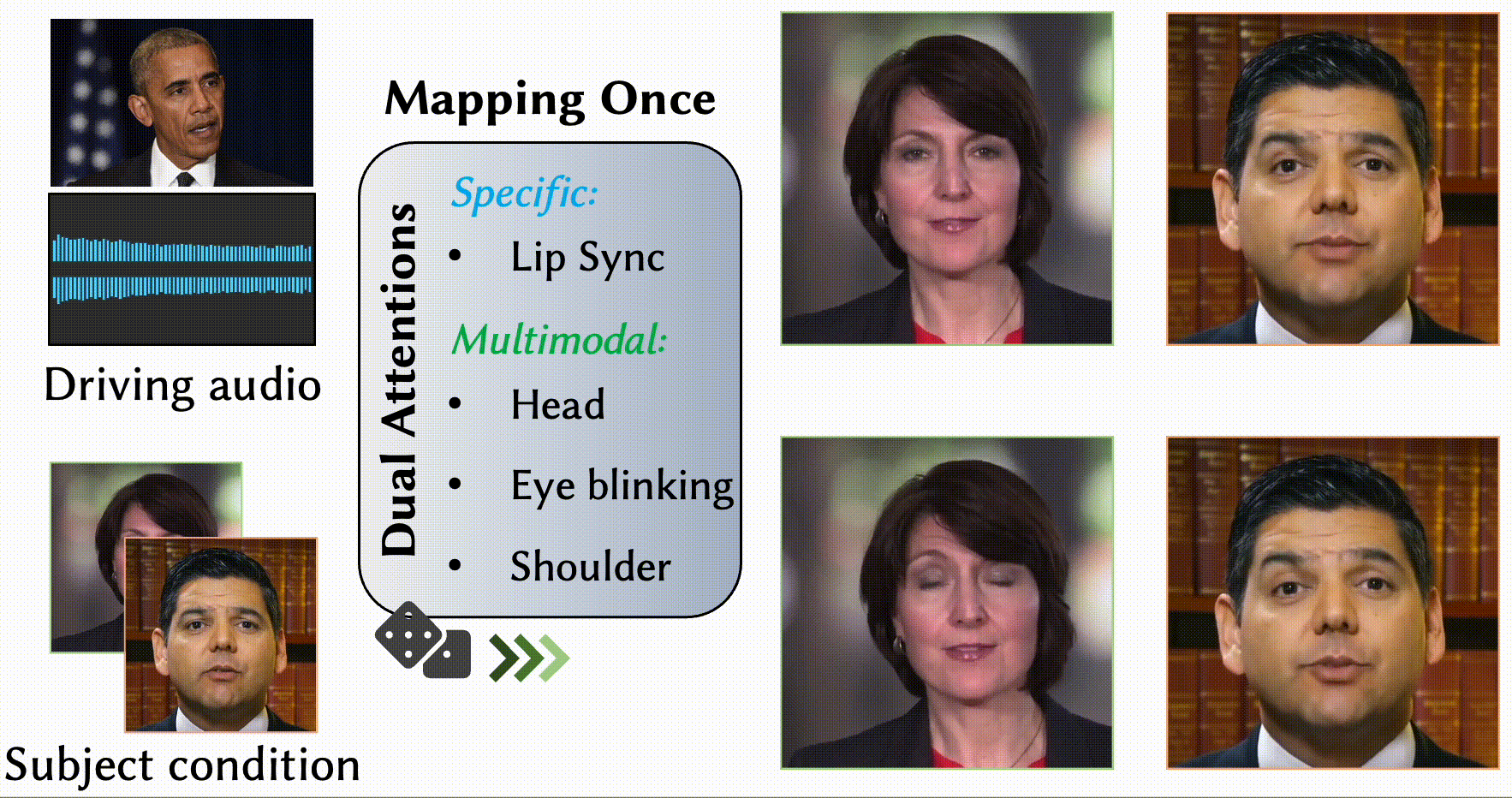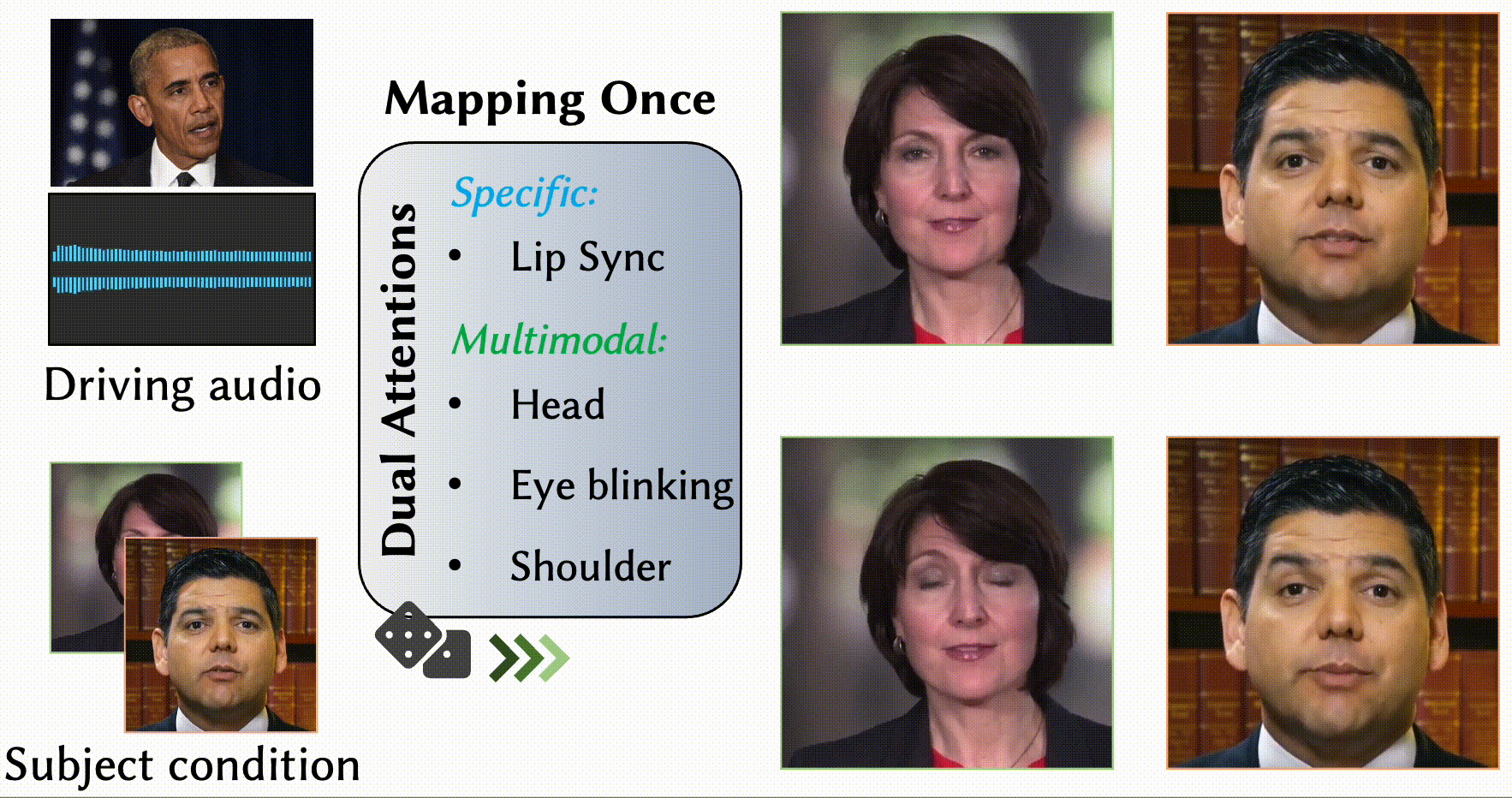
MODA: Mapping-Once Audio-driven Portrait Animation with Dual Attentions
Yunfei Liu, Lijian Lin, Fei Yu, Changyin Zhou, Yu Li
- We propose a unified system for multi-person, diverse, and high-fidelity talking portrait video generation.
- Extensive evaluations demonstrate that the proposed system produces more natural and realistic video portraits compared to previous methods.
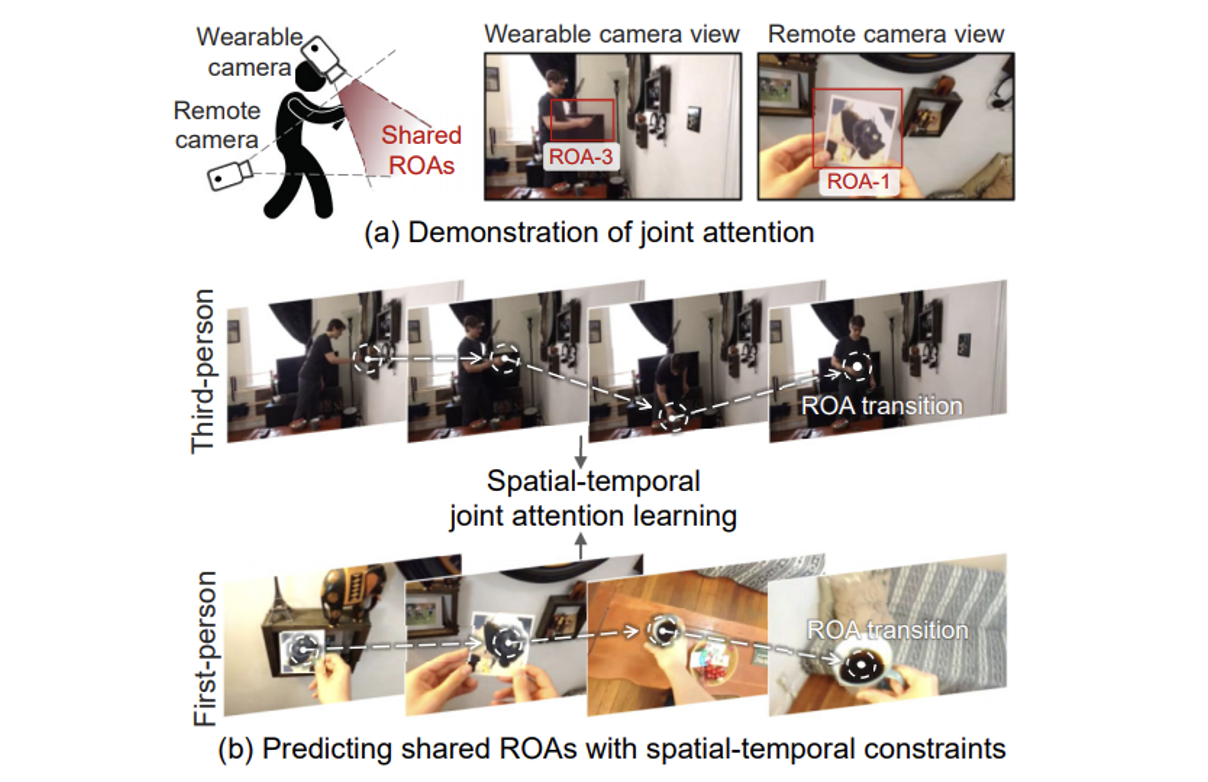
First- And Third-person Video Co-analysis By Learning Spatial-temporal Joint Attention
Huangyue Yu, Minjie Cai, Yunfei Liu, Feng Lu
Project | IF=17.730
- We propose a multi-branch deep network, which extracts cross-view joint attention and shared representation from static frames with spatial constraints, in a self-supervised and simultaneous manner.
- We demonstrate how the learnt joint information can benefit various applications.

GazeOnce: Real-Time Multi-Person Gaze Estimation
Mingfang Zhang, Yunfei Liu, Feng Lu
- GazeOnce is the first one-stage endto-end gaze estimation method.
- This unified framework not only offers a faster speed, but also provides a lower gaze estimation error compared with other SOTA methods.
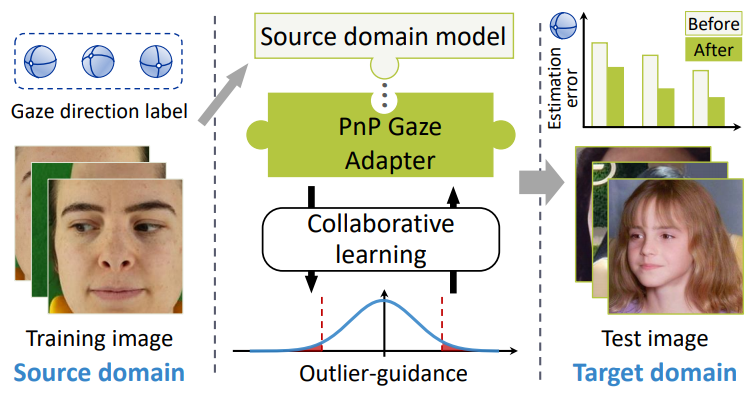
Generalizing Gaze Estimation with Outlier-guided Collaborative Adaptation
Yunfei Liu📌, Ruicong Liu📌, Haofei Wang, Feng Lu
- PnP-GA is an ensemble of networks that learn collaboratively with the guidance of outliers.
- Existing gaze estimation networks can be directly plugged into PnP-GA and generalize the algorithms to new domains.
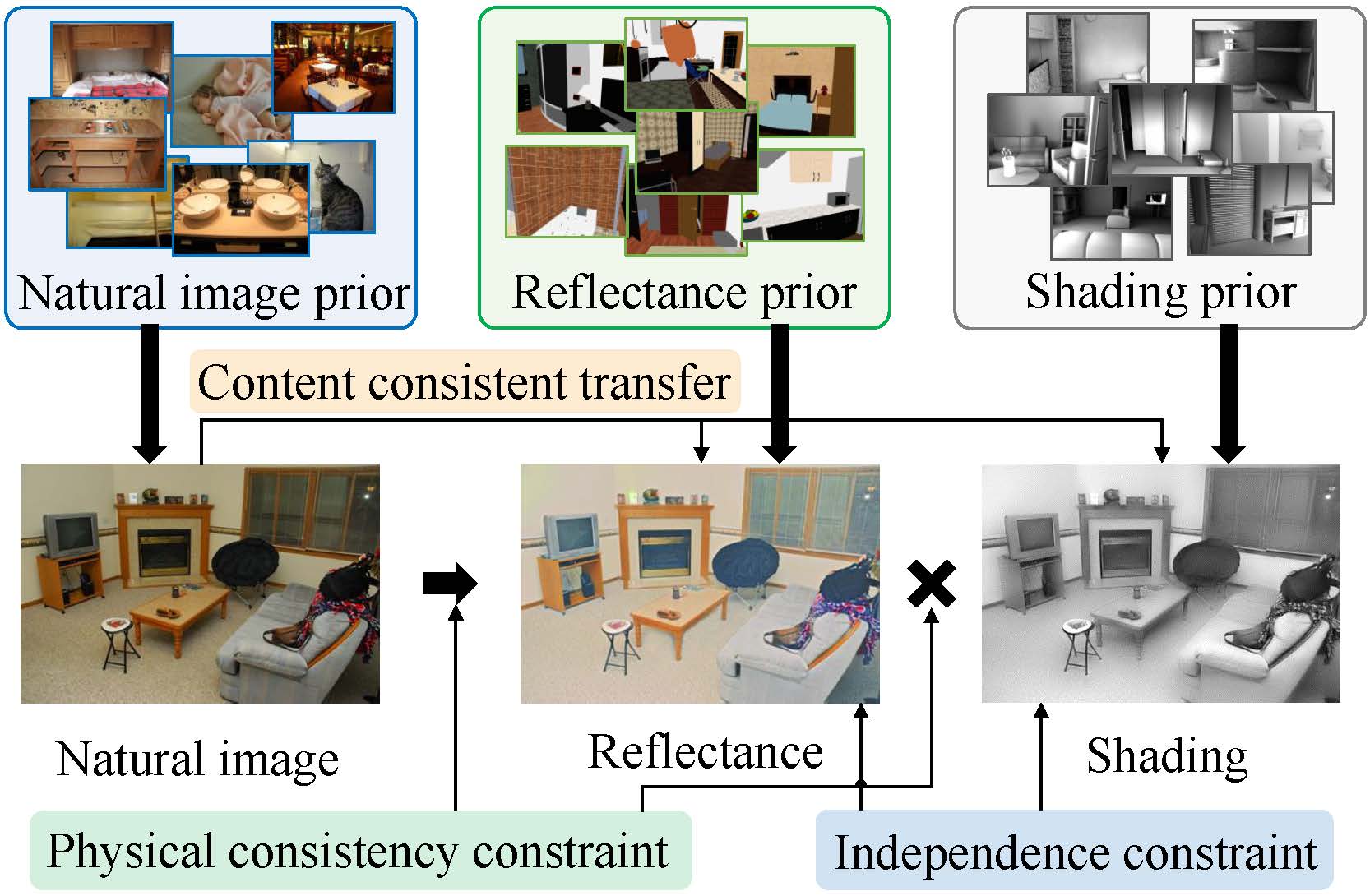
Unsupervised Learning for Intrinsic Image Decomposition from a Single Image
Yunfei Liu, Yu Li, Shaodi You, Feng Lu

- USI3D is the first intrinsic image decomposition method that learns from uncorrelected image sets.
- Academic Impact: This work is included by many low-level vision projects, such as Relighting4D
, IntrinsicHarmony, DIB-R++. Discussions in Zhihu.

Reflection Backdoor: A Natural Backdoor Attack on Deep Neural Networks
Yunfei Liu, Xingju Ma, James Bailey, Feng Lu
[Project | (Citations 750+)]
- We present a new type of backdoor attack: natural reflection phenomenon.
- Academic Impact: This work is included by many backdoor attack/defense works, Such as NAD
. This work is at the first place at google scholar .
-
TVCG 2025Qffusion: Controllable Portrait Video Editing via Quadrant-Grid Attention Learning, Maomao Li, Lijian Lin, Yunfei Liu📩, Ye Zhu, Yu Li ICCV 2025CanonSwap: High-Fidelity and Consistent Video Face Swapping via Canonical Space Modulation, Xiangyang Luo, Ye Zhu, Yunfei Liu, Lijian Lin, Cong Wan, Zijian Cai, Shao-Lun Huang, Yu LiAAAI 2025AnyTalk: Multi-modal Driven Multi-domain Talking Head Generation, Yu Wang, Yunfei Liu, Fa-Ting Hong, Meng Cao, Lijian Lin, Yu LiECCV 2024AddMe: Zero-shot Group-photo Synthesis by Inserting People into Scenes, Dongxu Yue, Maomao Li, Yunfei Liu, Ailing Zeng, Tianyu Yang, Qin Guo, Yu LiCVPR 2024A Video is Worth 256 Bases: Spatial-Temporal Expectation-Maximization Inversion for Zero-Shot Video Editing, Maomao Li, Yu Li, Tianyu Yang, Yunfei Liu, Dongxu Yue, Zhihui Lin, Dong XuICLR 2024GPAvatar: Generalizable and Precise Head Avatar from Image(s), Xuangeng Chu, Yu Li, Ailing Zeng, Tianyu Yang, Lijian Lin, Yunfei Liu, Tatsuya HaradaPRCV 2024Visibility Enhancement for Low-light Hazy Scenarios, Chaoqun Zhuang, Yunfei Liu, Sijia Wen, Feng Lu.ICCV 2023Accurate 3D Face Reconstruction with Facial Component Tokens, Tianke Zhang, Xuangeng Chu, Yunfei Liu, Lijian Lin, Zhendong Yang, et al..CVMJ 2023Discriminative feature encoding for intrinsic image decomposition, Zhongji Wang, Yunfei Liu, Feng Lu.CVPR 2022Generalizing Gaze Estimation with Rotation Consistency, Yiwei Bao, Yunfei Liu, Haofei Wang, Feng Lu.IEEE-VR 2022Reconstructing 3D Virtual Face with Eye Gaze from a Single Image, Jiadong Liang, Yunfei Liu, Feng Lu. [Oral]TOMM 2022Semantic Guided Single Image Reflection Removal, Yunfei Liu, Yu Li, Shaodi You, Feng Lu, GitHub.arXiv 2022Jitter Does Matter: Adapting Gaze Estimation to New Domains, Mingjie Xu, Haofei Wang, Yunfei Liu, Feng Lu.ISAMR 20213D Photography with One-shot Portrait Relighting, Yunfei Liu, Sijia Wen, Feng Lu.ISAMR 2021Edge-Guided Near-Eye Image Analysis for Head Mounted Displays, Zhimin Wang*, Yuxin Zhao*, Yunfei Liu, Feng Lu. [Oral] GitHub, Demo videoBMVC 2021Separating Content and Style for Unsupervised Image-to-Image Translation, Yunfei Liu, Haofei Wang, Yang Yue, Feng Lu. GitHub.arXiv 2021Unsupervised Two-Stage Anomaly Detection, Yunfei Liu, Chaoqun Zhuang, Feng Lu, GitHub.arXiv 2021Cloud Sphere: A 3D Shape Representation via Progressive Deformation, Zongji Wang, Yunfei Liu, Feng Lu.arXiv 2021Vulnerability of Appearance-based Gaze Estimation, Mingjie Xu, Haofei Wang, Yunfei Liu, Feng Lu.AAAI 2020Separate In Latent Space: Unsupervised Single Image Layer Separation, Yunfei Liu, Feng Lu. GitHub [Oral]ICPR 2020Adaptive Feature Fusion Network for Gaze Tracking in Mobile Tablets, Yiwei Bao, Yihua Cheng, Yunfei Liu, Feng Lu. GitHub.ACM-MM 2019What I See Is What You See: Joint Attention Learning for First and Third Person Video Co-analysis, Huangyue Yu, Minjie Cai, Yunfei Liu, Feng Lu.
🎖 Honors and Awards
-
Shenzhen Artificial Intelligence Natural Science Award, 2023
-
Shenzhen Pengcheng special talent award, 2023
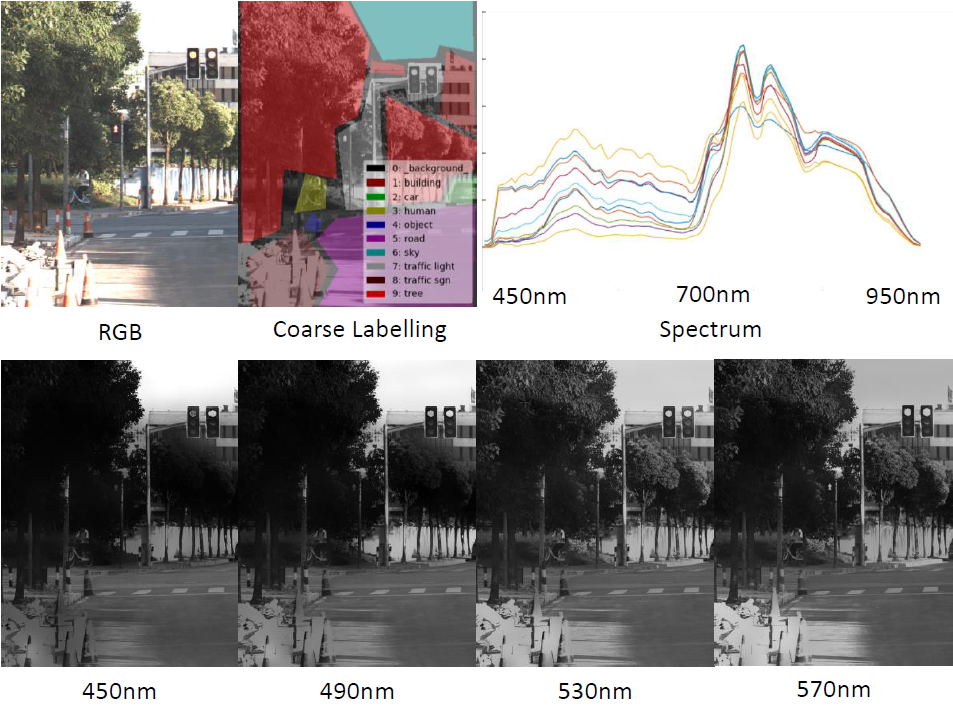
Winner of Hyperspectral City Challenge 1.0, Rank: 1.
Yunfei Liu
Project
- Adopt adopts multi-channel multi-spectum data to guide semantic segmentation for cityscapes.

Vertical Take-Off and Landing (VTOL) track. First prize
Yunfei Liu, Changjing Wang, Chao Ma, Haonan Zheng, Yongzhen Pan.
Project
- China Aeromodelling Design Challenge. Vertical Take-Off and Landing (VTOL) track. First prize, Rank: 6/70.
- 2021.10 National Scholarship.
- 2021.11 Principal scholarship.
📖 Educations
- 2017.09 - 2022.11, Beihang University, School of Computer Science and Engineering, State Key Labratory of Virtual Reality Technology and Systems.
- 2013.08 - 2017.06, Beijing Insitute of Technology, School of Computer Science and Technology.
💬 Invited Talks
- 2021.06, Visual intelligence for enhanced perception, Huawei internal talk
- 2021.06, Digital Image Processing, Beihang international class
- 2020.06, Deep learning interpretability, Meituan internal talk
💻 Internships
- 2022.03 - 2022.10, IDEA, Vistring Lab, Shenzhen, China.
- 2016.07 - 2017.05, DJI, Visual Perception Group, Shenzhen, China.